如同我們在Day 4講到自然語言生成時提到的,語言模型在做的就是將機率指向一個序列的文字。
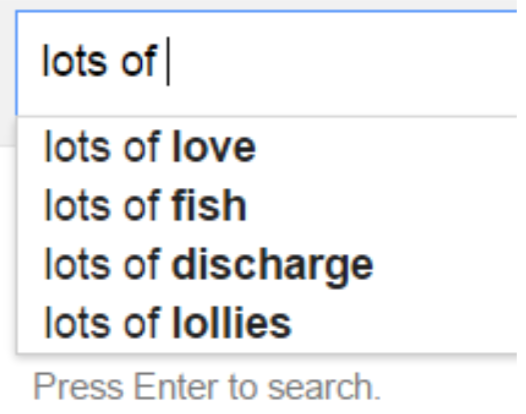
語言模型有許多延伸的應用,例如:語音辨識、拼字檢查、機器翻譯、查詢建議等。
要介紹語言模型,通常也會同時介紹N元語法 (N-gram)。N元語法是指「文本中連續出現的n個語詞」。常見的有n=1的unigram、n=2的bigram以及n=3的trigram model。

N-gram語言模型基於機率學,目標是取得一個m字序列的機率:
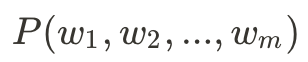
首先,我們透過連鎖律將聯合機率轉換為條件機率:
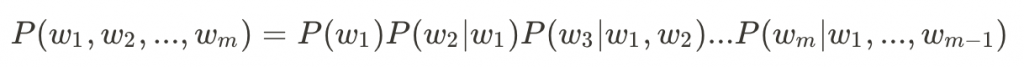
雖然轉換成了條件機率,但仍然有些棘手,因此我們再根據馬卡夫定理來簡化:
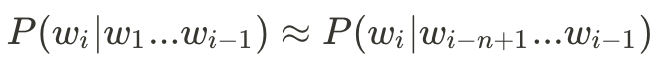
如此一來,我們要處理N-gram語言模型的公式便可簡化為:
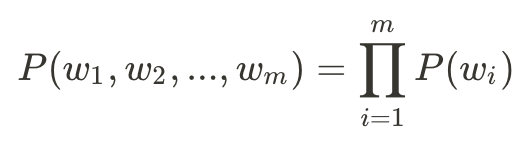
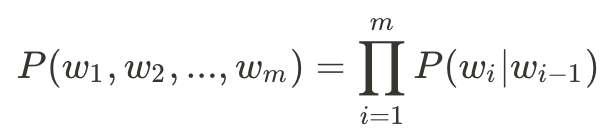
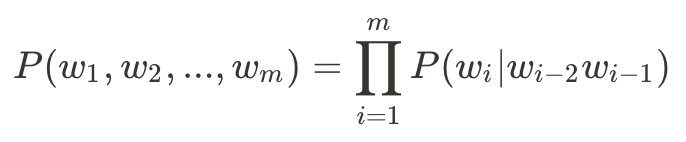
而我們要如何取得這些機率呢?根據文集當中出現的次數進行計算:
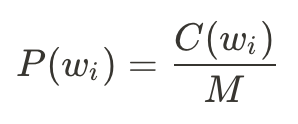
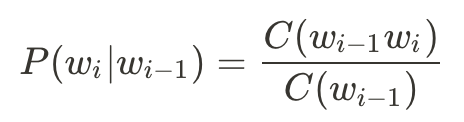
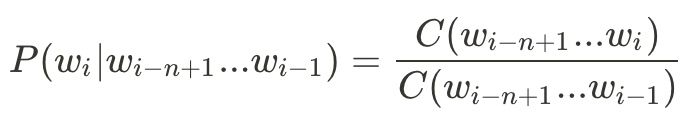
這裡寫了很多數學公式,雖然看起來很複雜,但仔細看其實是看得懂的(吧?)。
因為在Bigram以上的語言模型裡面會用考慮到前後文的關係,在句首和句尾的地方,為了把第一個字和最後一個字也都列入條件的考量當中,所以我們會需要在前後貼上special tag,舉一個trigram的例子:
假如我們文集中有以下句子:
<s> <s> yes no no no no yes </s><s> <s> no no no yes yes yes no </s>
我們想知道句子:<s> <s> yes no no yes </s>出現的機率。
這時我們要先取得每個字在trigram中出現的機率:
yes | <s> <s>) = 1/2no | <s> yes) = 1no | yes no) = 1/2yes | no no) = 2/5</s> | no yes) = 1/2我們把這些機率乘起來會得到:1/2 * 1 * 1/2 * 2/5 * 1/2 = 1/20 (0.05)。所以,照著我們的訓練文集,P(<s> <s> yes no no yes </s>)出現的機率是0.05。然而,單純這麼做存在著幾個問題:(1) 當文集資料量變大時,每個東西出現的機率會將得非常低,所得到的最終機率也會非常低;(2) 若是有個東西出現在文集的機率為零,任何東西乘以0為0,這句話出現的機率也會因此成為0,這樣的值是沒有意義的。在之後的文章中會利用Smoothing來解決以上的問題。

